개요
Proxmox VE 위에서 서비스를 분리할 때 VM 대신 LXC(Linux Container)를 주로 선택한다. 자체 커널을 올리지 않으니 메모리와 부팅 시간 오버헤드가 훨씬 작고, 서비스 단위로 격리하기에도 충분하다.
문제는 LXC 내부에서 다시 Docker를 돌리려 할 때 발생했다.
문제 상황
Unprivileged LXC 컨테이너를 생성하고, 내부에서 dockerd를 올리자마자 다음과 같은 에러가 쏟아졌다.
Error response from daemon: failed to create shim task:
OCI runtime create failed: container_linux.go:380:
starting container process caused: process_linux.go:545:
container init caused: rootfs_linux.go:76:
mounting "proc" to rootfs at "/proc" caused:
mount through procfd: permission denied
/proc와 /sys 같은 가상 파일시스템을 마운트하지 못하는 것이 핵심이었다.
원인 분석
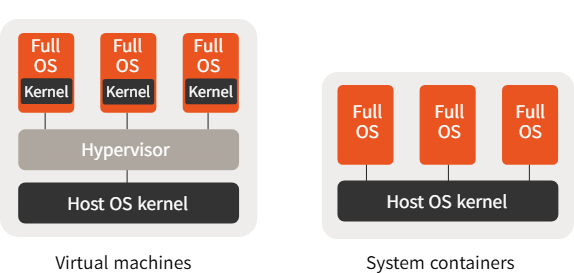
LXC와 VM의 격리 수준 차이를 이해하면 원인이 명확해진다.
VM은 하이퍼바이저가 가상 하드웨어를 에뮬레이션하므로 게스트 OS가 완전히 독립된 커널을 갖는다. 반면 LXC는 호스트(Proxmox)의 커널을 공유하고, 네임스페이스(namespace)와 cgroup으로 프로세스/파일시스템/네트워크 등을 격리하는 구조다.
Unprivileged LXC는 여기에 추가로 두 가지 보호 레이어가 붙는다.
- UID/GID remapping: 컨테이너 내부의 root(uid=0)가 호스트에서는 일반 사용자(uid=100000)로 매핑된다. 호스트 커널 자원에 실제 root로 접근하는 경로가 차단된다.
- AppArmor 프로파일: Proxmox는
lxc-container-default-cgns같은 AppArmor 프로파일을 컨테이너에 적용한다. 여기서/proc,/sys마운트 같은 민감한 syscall이 명시적으로 제한된다.
Docker 데몬은 자신이 관리하는 컨테이너를 위해 /proc, /sys, cgroup 등을 직접 마운트해야 한다. Unprivileged LXC 안에서는 이 마운트 권한이 없으므로 즉시 실패한다.
해결 과정
컨테이너 설정 파일(/etc/pve/lxc/<CTID>.conf)에 아래 두 줄을 추가했다.
features: nesting=1
nesting=1은 “이 컨테이너 안에서 또 다른 컨테이너(혹은 유사 격리 환경)를 허용한다”는 옵션이다. 내부적으로는 AppArmor 프로파일을 컨테이너 중첩에 적합한 것으로 전환하고, /proc와 /sys 마운트에 필요한 syscall 허용 범위를 넓힌다. UID remapping은 그대로 유지되기 때문에 호스트 레벨 보안은 크게 훼손되지 않는다.
설정 적용 후 컨테이너를 재시작하면 dockerd가 정상 기동된다.
정리
| 항목 | Unprivileged LXC (기본) | nesting=1 적용 후 |
|---|---|---|
| 호스트 커널 공유 | O | O |
| UID remapping | O (보안 유지) | O (보안 유지) |
| /proc, /sys 마운트 | 차단 | 허용 |
| Docker 실행 | 불가 | 가능 |
이번 트러블슈팅으로 LXC 격리 메커니즘을 구체적으로 파악하게 됐다. 단순히 “권한이 없어서”가 아니라, AppArmor 프로파일이 syscall 단위로 제어하고 있다는 것, 그리고 nesting 옵션이 그 프로파일을 어떻게 완화하는지까지 이해한 것이 핵심이다.
운영 환경에서는 LXC 안에 Docker를 넣는 구조 자체가 네임스페이스 중첩으로 복잡도를 높이므로, 가능하면 Docker 없이 LXC 단위로 서비스를 분리하는